" COVID-19 "
- Background
- Data
- The sequence name : SARS-CoV2
- The sequence number : 156
- The longest bp : 29927
- The shortest bp : 29409
- miRNA Annotation
- Alignment and Phylogenetic Tree
- CDS Sequence Extraction
- Useful Link
The coronavirus disease 2019 (COVID-19) has spread to 211 countries across the world, since the outbreak in mid-December 2019. COVID-19 is caused by the newly emerging coronavirus, SARS-CoV2, which is distinct from SARS-CoV for Severe acute respiratory syndrome (SARS) and MERS-CoV for Middle East respiratory syndrome (MERS).
Coronavirus SARS-CoV2 was first identified in in the city of Wuhan, the capital of Central ChinaˇŻs Hubei Province and causes respiratory illnesses, including atypical pneumonia. It is a positive-stranded RNA virus and its genome is around 30k nucleotides long. The overall genome organization of SARS-CoV2 is similar to that of beta-coronaviruses, which includes SARS-CoV, MERS-CoV and Bat-SL-CoV (Bat SARS-like coronaviruse). They have common open reading frames (ORFs), such as ORF1ab (enzymatic proteins), S (spike-surface glycoprotein), E (small envelope protein), M (matrix protein), N (nucleocapsid protein), as well as several nonstructural proteins.
ˇń At present, more than 200 SARS-CoV2 sequences are available in several public databases. To make use of them more efficiently, here we only collect the whole genome of SARS-CoV2 from the databases including GISAID, Genbank and NMDC. The used criteria for screening is that the sequence length is bigger than 29k bp; less than 1% NNNs overall and hosted in human. In total, we got 156 whole genome sequences of SARS-CoV2 from 17 countries, including China, South Korea, Japan, France, Italy, the United States, Canada, Australia.
A brief description of the dataset:ˇń In addition, KCDC (Korea Centers for Disease Control & Prevention) announces the information of COVID-19 patients and updates the data as soon as possible.
Data LinkWe obtained 16 new coronavirus sequences, and obtained the mature sequences of all viruses in miRbase, and then used the miRNA matures of the virus to perform a blast experiment in the coronavirus genome, extending the matched region of about 20bp to two segments by 200bp. After deleting the redundant sequences, there were 6 sequences left. Then, the hairpin structure containing the mature body was found by RNAfold. The sequence of the mature body sequence on one hairpin arm was selected into a total of four sequences, and finally the relevant miRNA precursor prediction tools were used to verify whether the selected sequence are new coronavirus miRNA precursor sequences.
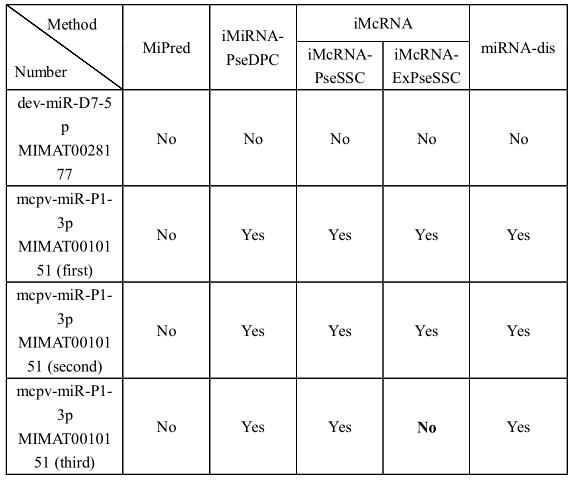
Prediction results of miRNA precursor sequences of new coronavirus: We used four miRNA precursor prediction tools to independently verify whether the four new coronavirus sequences were true miRNA precursors. The results are shown in figure 1. One of the four sequences is not a miRNA precursor sequence, and the remaining three should be miRNA precursor sequences.Table 1 Prediction results of four sequences
Location of miRNA precursor and mature sequences ( Data Download )
The sequences were selected from CNCB and GISAID, aligned by MAFFT and re-aligned by hand to get a better alignment, based on which a phylogenetic tree was constructed by MEGA-X.
Alignment Result and Phylogenetic Tree( Figure Download )

Figure 1 Phylogenetic Tree
The sequences were divided into dozens of segments respectively, each of which is represented as a color in the heat map behind the phylogenetic tree. The color is blacker if there are more mutations in one column than the others or in one color within the same column.
Mutation Visualization ( Figure Download )
{kind=link}
The sequence for Australia's Severe acute respiratory syndrome coronavirus 2 isolate the genome sequence of Australia/VIC01/2020 isolates (https://www.ncbi.nlm.nih.gov/nuccore/MT007544), It is also the reference genome of the team of Lachlan Coin and Sebastian Duchene from the department of microbiology and immunology of the university of Melbourne, Australia, which sequenced the RNA sequence of the virus directly by nanopore iii sequencing and used comparison. Currently, only the GTF file on NCBI has the annotation information of CDS (Coding DNA Sequence), which has been extracted and stored in the cds.fa file
Data Download